
This essay discusses:
- what is “traditional software”?
- what is “agentic software”?
- what makes agentic software useful?
I.
I define “traditional software” as a collection of digital tools that takes structured inputs (a table), transforms them into an interactive surface (a UI), lets a user act on them (features), and saves the result (another table).
Rinse and repeat: feature ideation, creation and distribution on top of an ever-expanding product surface. The best teams achieve “tasteful expansion” and product differentiation.
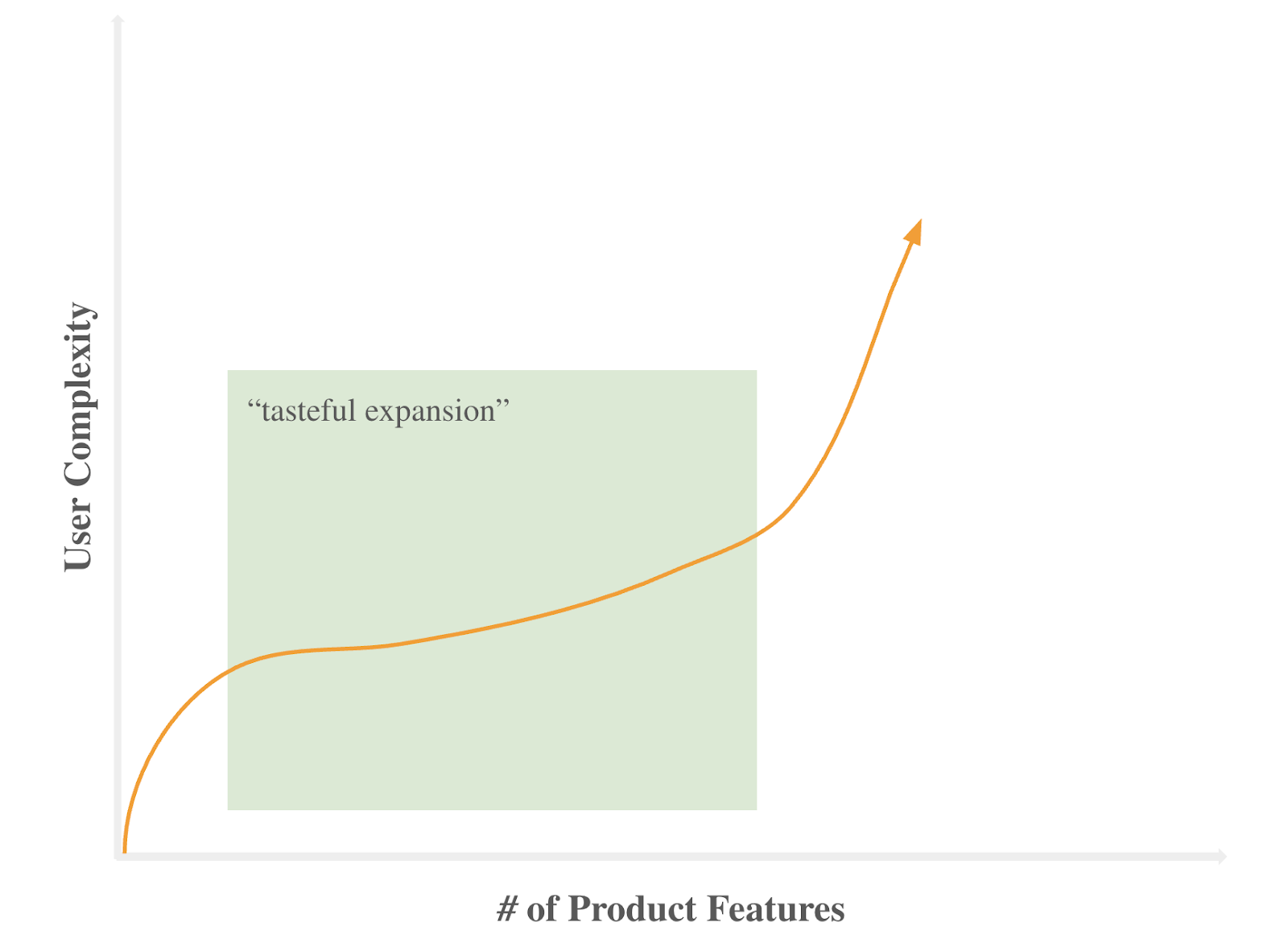
More tables, more transformations, more customers.
II.
I define “agentic software” as a system that completes a series of tasks at a specified accuracy given a defined set of inputs. Three dimensions can effectively differentiate such products: what tasks, what inputs, what accuracy.
Also worth making explicit is my working definition of successful “task completion”:
- At minimum, the expected outcome had someone done the task themselves
- At best, the ideal outcome without considering what someone would do themselves
A successful team must be intentional here. The minimum is observable by logging existing user actions and can be empirically validated in production. The best is an ambiguous function of domain expertise and context awareness that is admittedly difficult to define. My sense is targeting the minimum risks normalizing careless patterns rather than delivering productive automations. That said, the best requires conviction and is liable to fail catastrophically.
Consider someone monitoring a radar screen. Given object speed, altitude, and heading, an observer can model the decision space for an air traffic controller routing planes safely. Yet with the same inputs, a meteorologist using the same console can log a data point while checking their phone. Both are valid applications.
Now consider if radar data is delayed by five minutes. The controller now compensates by cross-referencing other instruments, communicating proactively, and adjusting every decision for the lag. The meteorologist neither notices nor cares. Both are valid responses.
Intuitively, success is defined very differently depending on the user persona, and different user personas have very different definitions for valid data. Less obvious is how traditional and agentic systems adapt.
Back to the radar screen.
Traditional software optimizes the display and interpretation layer.. A team might build a live graph of pipeline freshness that each persona can interpret differently. Over time, a team might iterate on said graph, adding customizations for different personas as needed.
Conversely, agentic software is entirely agnostic to the console and its display; the focus is on task completion. The challenge, then, is to reliably distinguish between tasks where stale data is catastrophic and tasks where it is irrelevant. That is hard to do for at least two reasons.
First, traditional software trains users to interpret and transform information within an opinionated and variable UI. Thus, to build agentic software, a team must understand 1/ what information is relevant to a given task and 2/ how users transform, filter and interpret said information for a given task. Second, traditional software relies on user discretion to parse a surface and ignore features surfacing irrelevant information.
Taken together: traditional software guarantees a bounded set of inputs and facilitates their transformation but does not promise outputs (i.e., user action). Agentic software inverts this. Inputs are variable, but given any set of them, agentic software will produce an output. Traditional software is constrained by inaction while agentic software is constrained by overreaction.
Useful agentic software will not:
- dictate a universal approximation of user intent
- evaluate success with an opinionated benchmark
- assume input relevance and fidelity
Useful agentic software will:
- collapse interaction to only input configuration
- structure inputs to accommodate any task
- obsess over input validation and ignore output customization